Gini 불순도와 정보이득이란?
[공지사항] 지킬블로그 안내드립니다.
지킬 블로그에 대하여 알아보겠습니다.
Gini 불순도란?
Gini 불순도는 분류 문제에서 의사 결정 나무 알고리즘을 사용할 때 중요한 개념입니다. Gini 불순도는 특정 노드에서 데이터 샘플의 혼합도를 측정하는 지표로, 샘플들이 서로 다른 클래스에 얼마나 섞였는지를 나타냅니다.
예를 들어, 통 안에 여러 개의 색깔이 섞여 있는 구슬이 있다고 가정해봅시다. 눈으로 봤을 때는 색깔이 얼마나 섞여 있는지 알 수 없지만, Gini 불순도를 계산하면 이를 수치화할 수 있습니다.
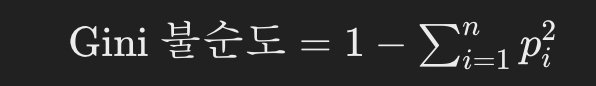
𝑝𝑖 는 클래스 𝑖의 비율입니다.
분할 기준
-
각 기능한 분할에 대해 각 지식 노드의 Gini 불순도를 계산다.
-
가중 평균 Gini 불순도를 구합니다. 이는 자식 노드들의 Gini 불순도와 각 지식 노드에 속하는 샘플 수를 곱한 값이다,
-
사장 낮은 가중 평균을 Gini 불순도를 가지는 분할을 선택합니다.
Gini 불순도는 의사 결정 나무에서 중요한 역할을 하는 지표로 노드 내 샘플의 혼합 정도를 나타냅니다.
그림을 통해 가장 적합한 분할을 찾고 데이터를 효과적으로 분류하면서 사용자가 분할 하기 싶게 했으면 좋겟습니다. Gini 불순도는 계산이 간단하고 효율적이어서 머신 러닝의 분류 문제를 해결 했으면 좋겠습니다.
정보 이득 이란
정보 이득은 ginit 불순도 처럼 의사 결정나무의 알고리즘에서 사용되는 중요한 지표 중에 하나입니다. 정보의 증가량을 측정하는 지표로 어떤 속성이 분류 작업에 가장 유용한지 판단하는 데 사용합니다.
의사 결정나무는 데이터르 분류 하는 것도 있고 여러개의 모델 중 하나로 분할되는 데이터를 통해 규칙을 학습하여 결정을 내리는데 사용됩니다. 데이터의 불활실성을 가장 많이 줄여주는 지를 나타내며 어떤 속성을 선택하는지 결정해야 합니다.
정보 이득 계산 방법
정보 이득은 엔트로피 이라는 기반으로 계산됩니다. 엔트로피는 데이터의 불확실성을 측정하는 지표로 값이 작을수록 데이터의 분포가 균일하게 에측하기 쉽게 해주는 역할 입니다.
첫번째 : 전체 데이터 집합의 엔트로피를 계산을 하고 클래스의 분포에 따라 불확실성을 측정해야합니다.
두번째 : 다음 각 속성을 기준으로 데이터를 분할 해야됩니다.
세번째: 분할된 각 데이터를 그룹에 대해 엔트로피르 계산합니다.
네번쨰 : 각분할의 엔트로피를 전체 데이터 집합의 엔트로피에서 빼서 정보 이득을 계산합니다.
다섯번째 : 가장 높은 정보 이득을 가진 속성을 선택하여 분할을 진행합니다.
정보 이득의 높은 속성을 선택하여 해당 속성으로 데이터를 분할 했을때 불확실성이 크게 감소하는 장점이 있습니다. 즉 분할 후의 각 그룹이 보다 순순하게 구서오디며 예측이 원할게 이루어 질 수 있습니다.
GIni 불순도 와 정보 이득 차이점
정보이득과 GIni 불순도는 의사 결정 나무에서 분할의 품질을 평가하는 데 사용 되는 중요한 지표입니다. 두 지표는 분할 후의 불순도 감소를 최적화 하는 방향으로 분할을 결정하여 모델의 분류 성능을 항상 시킵니다. 선택하는 지표에 따라 모델의 특성과 데이터에 따라 최적의 분할이 달라질 수 잇고 문제에 특성에 맞게 적절하고 지표를 선택하는 것이 중요 합니다.
댓글남기기