로지스틱 회귀 개념 머신러닝
[공지사항] 지킬블로그 안내드립니다.
지킬 블로그에 대하여 알아보겠습니다.
로지스틱 회귀 이란
입력 변수와 종속 변수 사이에 선형 관계가 있을 때 적용됩니다. 로지스틱 회귀는 선형 회귀와 달리 로지스틱 함수 또는 시그모이드 함수를 사용하여 확률을 예측 할 수 있고 시그모이드 함수는 0과 1 사이의 S자형 곡선을 갖는 함수로 다음 수식으로 정의 됩니다.
장점은 모델의 결과를 해석하기 쉽고 계수를 통해 각 변수의 영향을 파악 할 수 있다는 것 입니다. 계수를 통해 각 변수의 영향을 파악 할 수 있다는 것입니다. 또한 효과적으로 기본 모델로 사용 할 수 있지만 선형 결정 경계만으로 학습 할 수 있기 때문에 그렇게 까지 효율 적이지 않습니다.
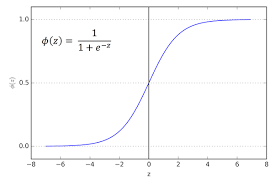
시그모이드 함수는 x 값이 점 점 증가하거나 감소하더라도 y 값이 항상 0 ~ 1 사이 값을 반환 한다는 특성을 가지고 있습니다. S 자형 곡선을 가지고 있습니다.
로지스틱 회귀는 이진 분류만 사용되는가?
로지스틱 회귀는 주로 이진 분류 문제에 사용 되지만, 다중 클래스 분류 에도 확장 될 수 있습니다. 모델의 결과를 해석하기 쉽다는 장점이 있고 또한
피쳐의 영향력을 해석하기 쉽고, 과적합을 방지하기 위한 규제 기법을 적용할 수 있습니다.
유방암 데이터 셋 이용한 로지스틱 회귀 예제
# 필요한 라이브러리 불러오기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# 유방암 데이터셋 불러오기
data = load_breast_cancer()
X = data.data
y = data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# 테스트 데이터로 예측
y_pred = model.predict(X_test_scaled)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 혼동 행렬 출력
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_matrix)
- 데이터셋 불러오기:
data = load_breast_cancer()
X = data.data
y = data.target
유방암 데이터셋을 불러옵니다. data.data는 입력 특성(feature)을, data.target은 해당 특성에 대한 레이블(label)을 나타냅니다.
- 데이터 분할:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
train_test_split 함수를 사용하여 데이터를 훈련 세트와 테스트 세트로 분할합니다. test_size 인자는 테스트 세트의 크기를 결정하고, random_state는 데이터를 나눌 때 셔플링을 위한 시드값입니다.
- 데이터 스케일링:
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
데이터의 스케일을 조정하기 위해 StandardScaler를 사용하여 각 특성의 평균을 0, 표준 편차를 1로 변환합니다. fit_transform 메서드는 훈련 데이터에 대해 스케일링을 수행하고, transform 메서드는 테스트 데이터에 적용합니다.
- 로지스틱 회귀 모델 학습:
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
LogisticRegression 클래스를 사용하여 로지스틱 회귀 모델을 초기화하고, 훈련 데이터에 모델을 학습시킵니다.
- 테스트 데이터로 예측:
y_pred = model.predict(X_test_scaled)
학습된 모델을 사용하여 테스트 데이터의 레이블을 예측합니다.
- 정확도 계산:
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
예측된 레이블과 실제 레이블 간의 정확도를 계산하고 출력합니다.
- 혼동 행렬 출력:
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_matrix)
혼동 행렬을 계산하여 출력합니다. 혼동 행렬은 모델이 각 클래스를 얼마나 정확하게 분류했는지를 나타내는 행렬입니다.
댓글남기기